In a world powered by amazing technology, Artificial Intelligence (AI) has become a game-changer. It’s transforming industries and personal experiences alike. But as I dived into the world of AI, I realized something important: before we dive in, we need to understand what AI is all about. This understanding became the key to my journey in recognizing just how crucial it is to grasp AI before diving in. In this article, I’ll share why this knowledge isn’t just handy, but downright essential.
In an era dominated by rapid technological advancements, Artificial Intelligence has emerged as a transformative force across various industries. From healthcare to finance, and from marketing to autonomous vehicles, AI is reshaping the way we live and work. However, with this surge in AI adoption comes the pressing need to address security concerns. In this article, we’ll delve into why prioritizing security when using AI is paramount for both individuals and organizations.
Protecting Sensitive Data
One of the most critical aspects of AI security is safeguarding sensitive information. AI systems often process vast amounts of data, ranging from personal identification details to confidential business records. A security breach can result in severe consequences, including financial loss, reputational damage, and legal liabilities. Implementing robust security measures is essential to ensure the protection of this valuable data.
As AI systems become more integrated into our daily lives, they also become attractive targets for cybercriminals. Malicious actors may attempt to exploit vulnerabilities in AI models or manipulate them for nefarious purposes. This could lead to outcomes such as misinformation, financial fraud, or even physical harm in cases involving autonomous systems. Security measures like encryption, access controls, and regular vulnerability assessments are crucial in safeguarding against such attacks.
Ethical considerations are paramount in the development and deployment of AI. Security measures play a significant role in upholding ethical standards. This includes preventing biased or discriminatory outcomes, ensuring transparency in decision-making, and respecting privacy rights. A secure AI system not only protects against external threats but also ensures that the technology is used responsibly and in accordance with ethical guidelines.
Mitigating Model Poisoning and Adversarial Attacks
AI models are susceptible to attacks aimed at manipulating their behavior. Model poisoning involves feeding deceptive data to the training process, which can compromise the model’s accuracy and integrity. Adversarial attacks involve subtly modifying input data to mislead the AI system’s output. By implementing security measures such as robust model validation and continuous monitoring, organizations can effectively mitigate these risks.
Trust is a cornerstone of any successful AI deployment. Users, whether they are consumers or stakeholders within an organization, need to have confidence in the AI system’s reliability and security. Implementing comprehensive security measures not only protects against potential breaches but also fosters trust in the technology, driving greater adoption and acceptance.
In an increasingly AI-driven world, the importance of security cannot be overstated. Protecting sensitive data, guarding against malicious attacks, ensuring ethical use, mitigating adversarial attacks, and building trust are all vital aspects of AI security. By prioritizing security measures in the development, deployment, and maintenance of AI systems, we can unlock the full potential of this transformative technology while minimizing risks and ensuring a safer, more reliable future. Remember, the benefits of AI can only be fully realized in an environment where security is a top priority.
Apologies, everyone! I’ve been a bit MIA lately due to a time crunch, but that’s about to change.
Are you planning to lift and shift VMs into the Cloud? Or have you done migration and now looking for a way how to scale them automatically?
Well, this article can be right for you!
When it comes to lifting and shifting the application and/or services hosted on the Virtual Machines (VM) from an on-premise environment to the Cloud, building a strategy and design of how to achieve some sort of automatization in VM scaling can be a challenging task.
In general, some type of scalability can be achieved with Virtual Machines as they are but it’s going to be very inopportune.
That’s why it is very important to work on cloud-based infrastructure design prior to the lifting-and-shifting process itself. And remember, VM scaling needs to happen automatically.
The approach I like to teach others is to automate everything that follows repetitive cycles.
But hang on, what if I scale up horizontally in the Cloud by adding extra HW resources (RAM, CPU) to logical machine computing power hosting my VM? .. Yes, this may work but with some scripting to be done first and that is less likely going to be repetitive with the same set of input properties…
But what if full scaling automatization can be accomplished with a higher running cost efficiency and as little configuration work as possible?
Yes, that is all possible these days and I am going to share how to use one of the options from the market.
The options I liked to pursue one project of mine is coming from the Microsoft Azure Resources stash.
Why is that?
It’s not a secret that I’ve worked with Azure since the early saga beginning. Therefore, I have built a long experience with the Azure platform. On the other hand, I have to admit that Azure Software Engineers have done a great job of building platform APIs and Web Wide UX/UI interface (Azure Portal) to make this process seamless and as easy to use as possible. More on my driving decision factors later …
Let’s get started
The Azure resources I have been mentioning here in the prologue are:
Every project has different needs and challenges coming from the business domain requirements. More importantly, rational justification on the economical side of the project complexity is mostly the driver of the project’s technological path in the design stage.
For this project, I was lucky because the customer I designed this solution for had part of the business applications and services in Azure already. Also, the customer big ambitious plans to migrate everything else from an on-premise data center to the Cloud in the near time horizon just made my decision more sealed, and therefore Cloud in Azure was the way to go.
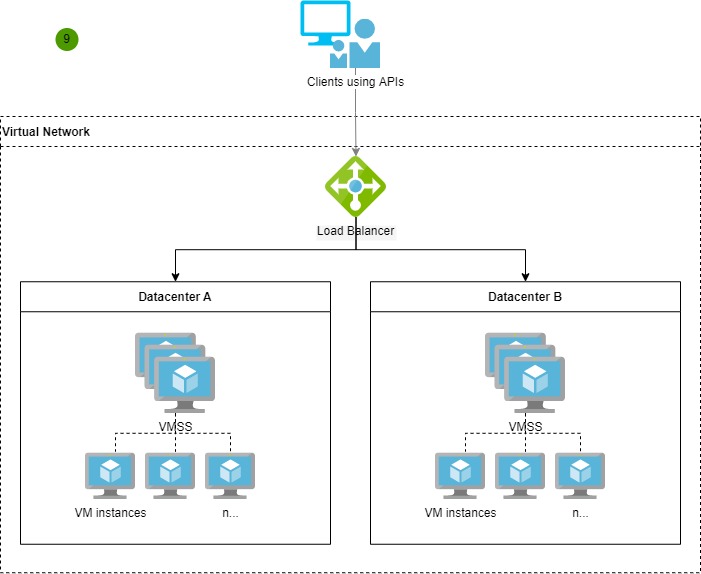
Infrastructure diagram
Let’s get a better understanding of the designed system infrastructure from the simplified infrastructure diagram below.
Take it with a grain of salt as the main purpose of it is to highlight the main components used in the project and discuss these in this post.
VMSS simplified infrastructure diagram
What I like most about the selected Azure stack
VM redundancy across multiple data centers globally
has the ability to multiply VM instances as needed with an option to resize the instance computing power when needed (RAM, CPU, etc. => vertical scaling)
high service availability and resilience (subject to infrastructure design – in my case, I provisioned a total of two VMSSs, one geographically different data center each)
I like the flexibility of building my rules in VMSS on which the system decides whether VM instances go up or down in the quantity
Azure traffic balancer can be linked to VMSS easily
the VMSS service can provision up to 600 VM instances (and that is a lot!)
the Azure Compute Gallery (ACG) service is able to replicate images globally, supports image versioning and auto-deployment of the latest model to VM running instance (and that was a hot feature for me)
Steps to Provision Services in Azure
In a nutshell, follow these steps to provision Azure services and build the cloud infrastructure from the ground up:
Lift and shift the VM into Azure (I can recommend using the Azure Migrate service to start this process)
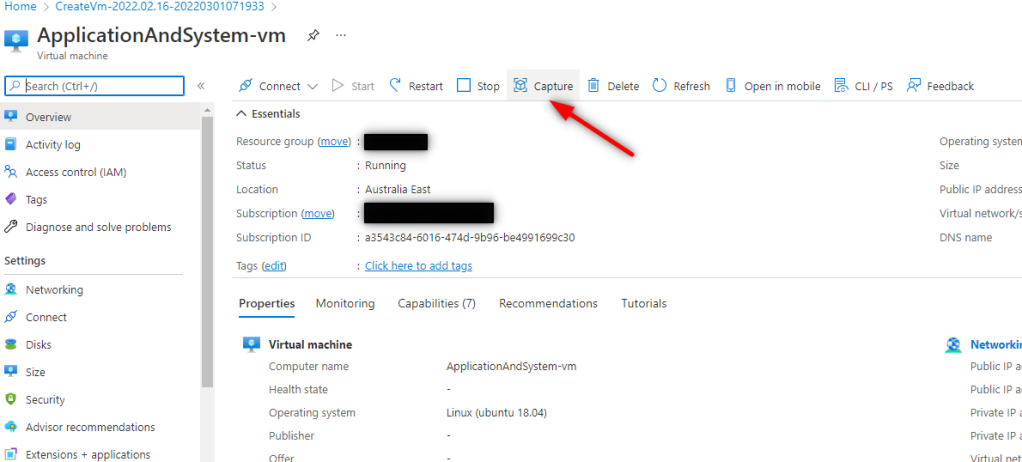
Go to the running instance of the VM and capture and generalize the image of the migrated VM
Capturing VM state into the image, Azure portal
Selecting an option to Generalized VM captured state into the image
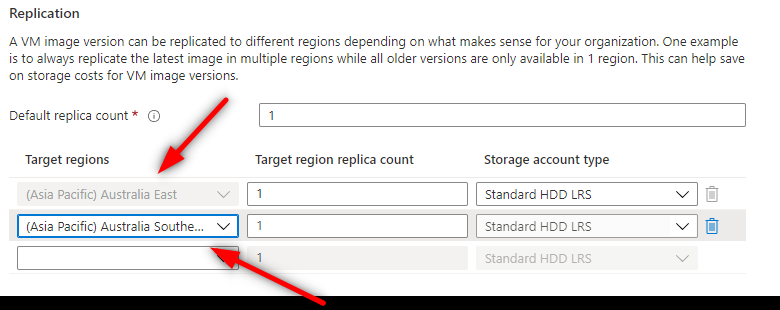
Create two replicated images (for one datacentre each)
Two replicated images setting
Save the image into Azure Compute Gallery created in step 2
Create two new Azure resources: Virtual Machine Scale Set (in geographically different data centers as per settings in ‘Target regions’ in step 4 for Scaleset redundancy capabilities)
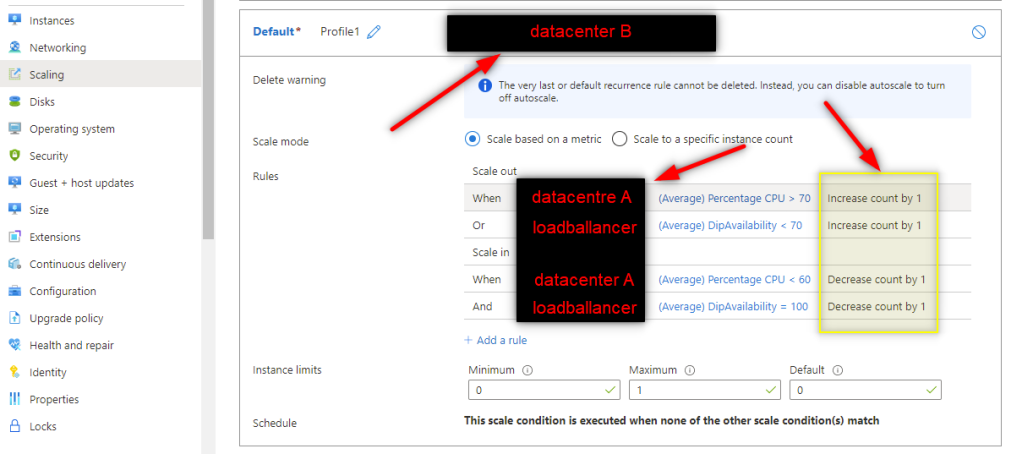
Create scale-out/in rules in VMSS
Scale-out/in VMSS rules example
The screenshot image below shows the example of setting up the Scaling rules for one of the VMSS instances.
VMSS scaling rules example
As you can see in my default profile in the picture above, this VMSS instance is not running any VM instances by default (Minimum = 0). But rather, spins up some (scaling out) based on these criteria:
The main VMSS instance hosted in datacenter A increases on average CPU (or)
The load balancer availability drops below 70% in a given timeframe
Very similar rules are used in the reverse process, aka scaling in.
If you’re planning to use a similar concept in your solution, count a VM operation system booting time in your metrics if high VM-hosted service availability and responsiveness are important to meet.
Microsoft Azure recently introduced a new feature called Predictive autoscale with Pre-launch setup (at the time of writing this article in preview only) which should solve a VM boot time issue for most of the use case scenarios. It works based on cyclical workload patterns determined by machine learning and predicts scaling out needs action in advance.
I like to say, that using Machine learning capabilities in this sort of behavior analysis is a very smart move from Microsoft forward.
I think VMSS has a lot to offer to businesses starting their journey to the Cloud.
The process of setting the infrastructure up is not complicated and can be done over UI/UX design in the Azure portal in no time. The VMSS scaling rules offer a lot of options to choose from and the level of integration with other types of Azure resources is on a very mature level, too.
Thanks for staying, subscribe to my blog and leave me a comment below.
When I first delved into Rust, it felt like stepping into a world where safety, performance, and developer experience converge in harmony. As someone who’s often wrestled with the complexities of memory management, runtime bugs, and performance bottlenecks in other languages, Rust has been a game-changer. It has not only helped me reduce running costs for applications but also significantly improved their security and stability.
Let me take you on a journey through what makes Rust truly stand out, chapter by chapter, highlighting its most powerful features.
Zero-Cost Abstractions: Performance Without Sacrifice
One of Rust’s most impressive features is its zero-cost abstractions. High-level constructs like iterators and smart pointers provide clarity and elegance to your code but with zero performance overhead. This means you get the power of abstraction without sacrificing efficiency—a dream come true for anyone managing resource-heavy applications.
For me, this has translated into writing expressive code that’s both readable and as efficient as handcrafted low-level implementations. Rust makes me feel like I’m coding with superpowers, optimizing applications without even breaking a sweat.
[RUST]
fn main() {
let numbers = vec![1, 2, 3, 4, 5];
let doubled: Vec<i32> = numbers.iter().map(|x| x * 2).collect();
println!("{:?}", doubled); // Output: [2, 4, 6, 8, 10]
}
This example demonstrates how Rust’s iterators provide high-level abstraction for traversing and transforming collections without performance overhead.
Ownership Model: Memory Safety Reinvented
Rust’s ownership model was a revelation for me. It ensures every value has a single owner, and once that owner goes out of scope, the memory is freed—no garbage collector, no fuss.
This elegant approach eliminates bugs like dangling pointers, double frees, and memory leaks. For anyone who’s spent late nights debugging memory issues (like I have), Rust feels like the safety net you didn’t know you needed. It’s not just about reducing bugs; it’s about coding with peace of mind.
[RUST]
fn main() {
let s = String::from("hello"); // s owns the memory
let s1 = s; // Ownership is transferred to s1
// println!("{}", s); // Uncommenting this line causes a compile error
println!("{}", s1); // Correct, as s1 now owns the memory
}
This shows how Rust ensures memory safety by transferring ownership, preventing use-after-free errors.
Borrowing Rules: Sharing Done Right
Building on the ownership model, Rust introduces borrowing rules, allowing you to share data through references without taking ownership. But there’s a catch (a good one): Rust enforces strict rules around lifetimes and mutability, ensuring your references never outlive the data they point to.
This might sound restrictive at first, but trust me—it’s liberating. Rust helps you avoid data races and other concurrency nightmares, making multi-threaded programming surprisingly smooth.
[RUST]
fn main() {
let mut x = 10;
{
let r1 = &x; // Immutable borrow
println!("r1: {}", r1);
// let r2 = &mut x; // Uncommenting this line causes a compile error
}
let r3 = &mut x; // Mutable borrow after immutable borrow scope ends
*r3 += 1;
println!("x: {}", x);
}
This code highlights borrowing rules, showcasing how Rust prevents data races by enforcing strict borrowing lifetimes.
Algebraic Data Types (ADTs): Expressive and Error-Free
Rust’s Algebraic Data Types (ADTs) are like a Swiss Army knife for designing robust data models. Whether it’s enums, structs, or tuples, Rust lets you express relationships concisely.
The Option and Result types are my personal favorites. They force you to handle errors explicitly, reducing those frustrating runtime surprises. Combined with pattern matching, Rust makes handling edge cases a breeze. ADTs in Rust don’t just make code cleaner—they make it safer.
[RUST]
fn divide(a: i32, b: i32) -> Option<i32> {
if b == 0 {
None
} else {
Some(a / b)
}
}
fn main() {
match divide(10, 2) {
Some(result) => println!("Result: {}", result),
None => println!("Cannot divide by zero!"),
}
}
Rust’s Option type ensures that edge cases like division by zero are handled explicitly, reducing runtime errors.
Polymorphism: Traits Over Classes
Rust’s approach to polymorphism is refreshingly different. Forget bloated inheritance hierarchies—Rust uses traits to define shared behavior across types. This static dispatch ensures zero runtime cost.
When I need flexibility, Rust also offers dynamic dispatch via dyn Trait. It’s the best of both worlds—flexibility where needed and performance everywhere else.
[RUST]
trait Area {
fn area(&self) -> f64;
}
struct Circle {
radius: f64,
}
struct Rectangle {
width: f64,
height: f64,
}
impl Area for Circle {
fn area(&self) -> f64 {
3.14 * self.radius * self.radius
}
}
impl Area for Rectangle {
fn area(&self) -> f64 {
self.width * self.height
}
}
fn print_area<T: Area>(shape: T) {
println!("Area: {}", shape.area());
}
fn main() {
let circle = Circle { radius: 5.0 };
let rectangle = Rectangle { width: 4.0, height: 3.0 };
print_area(circle);
print_area(rectangle);
}
This demonstrates Rust’s trait-based polymorphism, allowing shared behavior across different types.
Async Programming: Concurrency with Confidence
Rust’s async/await model is a masterpiece of design. Writing asynchronous code that feels synchronous is a joy, especially when you know Rust’s ownership rules are keeping your data safe.
For my high-throughput projects, Rust’s lightweight async tasks have been a game-changer. I’ve seen noticeable improvements in scalability and responsiveness, proving Rust isn’t just about safety—it’s about speed, too.
Using the Tokio runtime, Rust enables asynchronous programming with minimal overhead, ideal for scalable applications.
Meta Programming: Automate the Boring Stuff
Rust’s support for meta-programming is a lifesaver. With procedural macros and attributes, Rust automates repetitive tasks elegantly.
One standout for me has been the serde library, which uses macros to simplify serialization and deserialization. It’s like having an extra pair of hands, ensuring you can focus on logic rather than boilerplate.
Macros: Power and Simplicity
Rust’s macros are not just about simple text replacement; they’re a gateway to reusable, efficient patterns. Whether it’s creating custom DSLs or avoiding code duplication, macros have saved me countless hours.
What I love most is how declarative macros make the complex simple, ensuring my codebase remains DRY (Don’t Repeat Yourself) without becoming cryptic.
Rust’s macros simplify repetitive code, boosting productivity without runtime costs.
Cargo: Your New Best Friend
Managing dependencies and builds can often feel like a chore, but Rust’s Cargo turns it into a seamless experience. From managing dependencies to building projects and running tests, Cargo is the all-in-one tool I never knew I needed.
I particularly appreciate its integration with crates.io, Rust’s package registry. Finding and using libraries is intuitive and hassle-free, leaving me more time to focus on building features.
[RUST]
[dependencies]
tokio = { version = "1.0", features = ["full"] }
serde = { version = "1.0", features = ["derive"] }
With Cargo, adding dependencies is as simple as updating the Cargo.toml file. Here, tokio is used for asynchronous programming and serde for data serialization.
Why I’m Sticking with Rust
Rust has redefined what I expect from a programming language. Its combination of safety, performance, and developer-friendly tools has allowed me to build applications that are not only faster and more secure but also more cost-efficient.
If you’re still unsure whether Rust is worth the learning curve, let me leave you with this: Rust isn’t just a language—it’s a way to write code you can be proud of. It’s about building software that stands the test of time, with fewer bugs and better resource efficiency.
Here’s to building the future—one safe, efficient, and high-performance Rust program at a time. 🚀
Highlighted Features in Summary: Wrap-up
Zero-Cost Abstractions: Write expressive code without runtime overhead.
Ownership Model: Memory safety without garbage collection.
Borrowing Rules: No data races; safe and efficient memory sharing.
Algebraic Data Types (ADTs): Cleaner, safer error handling.
As a part of one work for one of my Big Data Warehouse, clients were to review and automate the ETL data pipeline to gain a better time2money efficiency in the current process the client’s data team was repeating for several months.
After running a discovery phase, I found that 36% of the time for ETL to run was spent on the Raw data file preparation stage.
Most (30%) spent on renaming files. This process was just semimanual and with a high risk for human error. Wow…
Anyway, with the right level of empathy, you may guess that the data team focus was given to higher priority tasks, and the time inefficiency of ETL pipelines was just tolerated compromise at that time.
No blame 🙂
Challenge description and solution
The Root Raw folder file structure was using a variant number of the nested folders in the folder hierarchy. Pretty confusing structure for someone new, to be honest.
So trying to find some sort of folder/file pattern did not sound like a viable option to me. Luckily, the raw data file names issued by 3rd party suppliers were consistent in one used naming convention, and therefore using a regular expression and PowerShell was my best bet to start with first.
The objective of this exercise was to remove the PAF2_V postfix from the file name of this naming convention PAF2_V<version of data extract>_<data context type>.DAT.
For an example, this file name:
PAF2_V2022Q1V01_ABBREVIATIONS.DAT
must become:
ABBREVIATIONS.DAT
This is an example of the fragment of the file names and hierarchy:
The breakdown structure of the PowerShell command:
Get-ChildItem -Filter “PAF2_*.DAT”– the command gets and filters out all files not having PAF2_ prefix and .DAT extension from the list
-Recurse – parameter used here for the recursive type of search over the folder/file hierarchy
Rename-Item -NewName {$_.Name -replace – the command renames all files by replacing found substring in the file name with some another
^(?:[^_]+_){2} – regular expression to find the substring in the string used for file name (to be replaced by empty string [”] eventually). As you can see, the substring search expression counts the number of separator characters ‘_’ in the string. The match becomes after the second occurrence.
Thanks for staying, subscribe to my blog, and leave me a comment below.
The running cost on some of the Azure resources (and licenses) can be massive and can cause a lot of frustration to a new starting business.
Therefore, I do always talk to my clients and try to find the best solution fitting their current needs. Then following the strategy of organic growth is the best way how to keep costs down while following the business transformation with technology into the mature and profitable one in the future.
In this article, I am going to explain how to cut Azure resource costs down from 50 – 70% depending on the resource type and length of commitment.
Where to start?
Azure has a very smart way of how to keep the customer’s engagement for years. I admire this strategy because creates a really good value for both parties (customer and provider).
If you haven’t heard about Azure Reservations it’s a good time to start your home research with this link.
In nutshell, you pay less for the Azure resource based on pre-purchased Reservations in years. That means that a longer commitment with the resource you make is less expensive it is going to get.
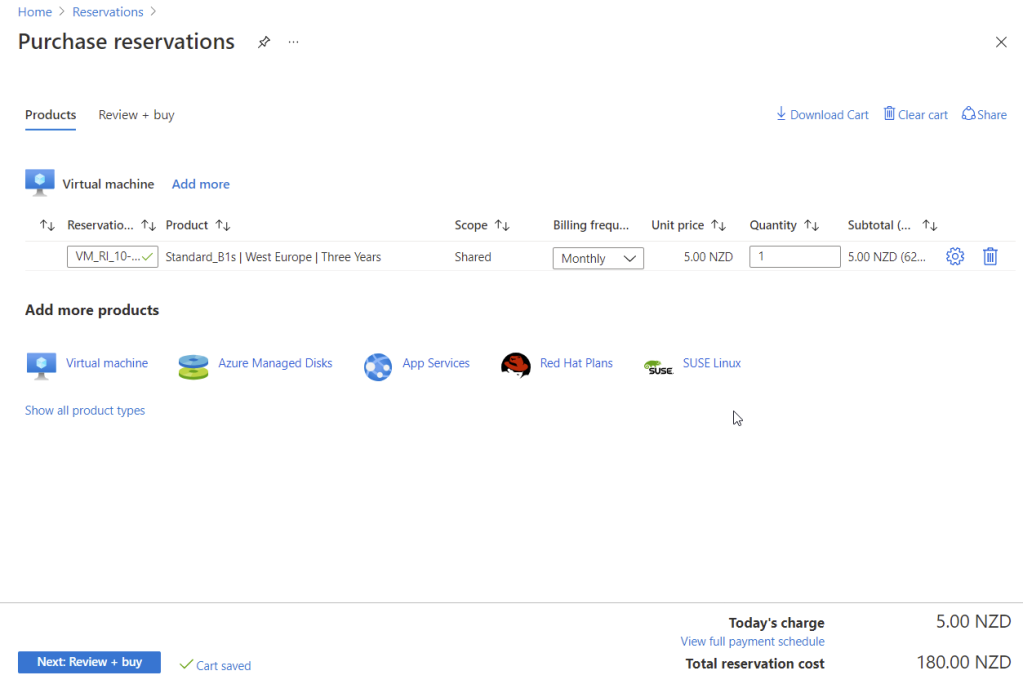
How to order Reservation in the Azure portal
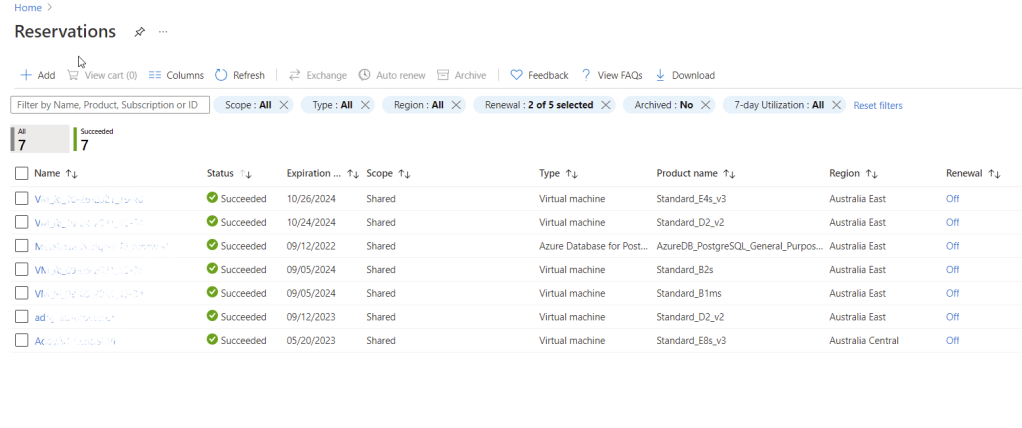
1. Log in to the Azure portal and search for ‘Reservations’. Select the Reservations option from the list and you should be able to see this page like in the picture below:
This is the current list of all reservations I have for one of my clients
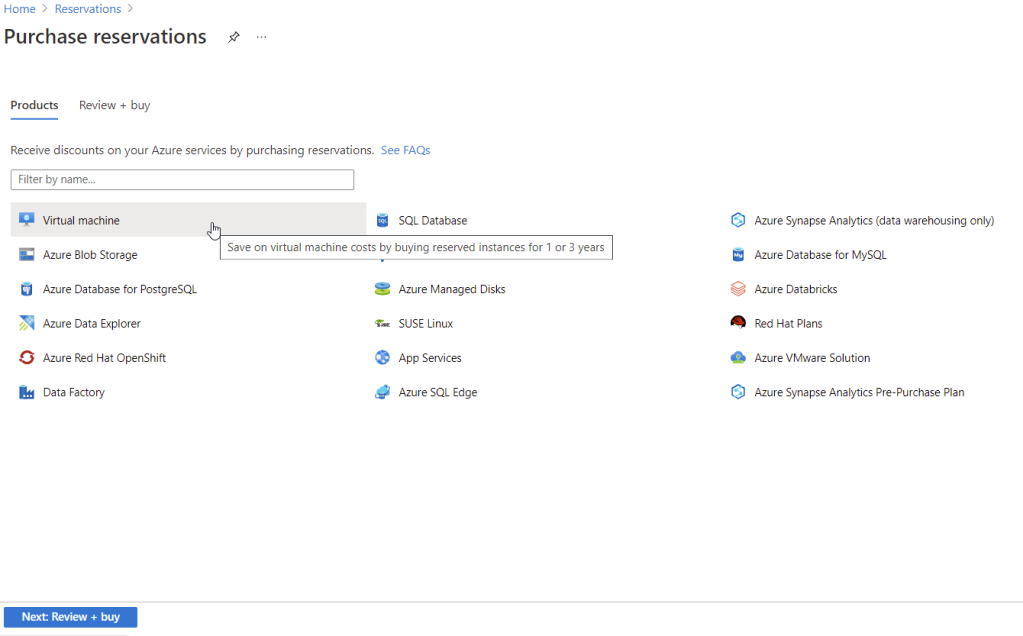
2. Click on the ‘plus’ icon in the top left corner. You will be redirected to this page as shown in the picture below:
List of resources to choose from
3. Select a resource you like to reserve from the list (I chose Virtual Machine)
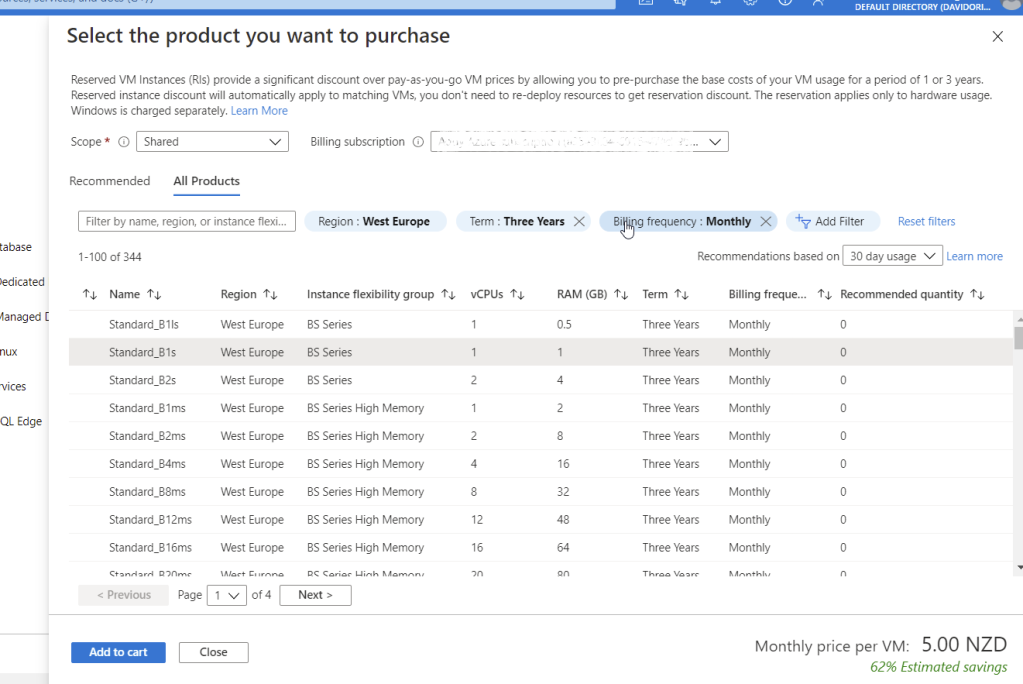
4. If you currently hosting some VM (as in my case) in Azure without Reservation, this tool does the filtering of the size of the VM automatically on the next page for you based on real-time utilization of that VM – that is smart!
5. Refine your selection in the next window by selecting the exact instance you like to reserve like in the picture below. This step is brilliant. It gives you an exact quote of how much it is going to cost you and what savings you are getting with a selected time commitment!
Available VM sizes with a price quote and estimate saving
6. Review the order and click ‘Review + Buy’ as is shown in the picture below:
Review order and purchase the reservation
7. … and we are done! You can monitor the overall Reservation utilization on the resource on the same page later on.
The process flow thanks to MS UX and UI is very intuitive, fast, and clear. Tell me your thoughts in the comments below!
Changing mind after purchase?
Unfortunately, there is some cost associated if want to cancel after purchasing the Reservation.
But, what I would recommend doing instead is trying to do a Reservation exchange!
Yep, you hear me right, you can exchange the Reservation for some other one as long as the purchasing price is not lower than the original one.
I think it’s brilliant and saves a lot of fiddling around on cost management when business strategy changes!
Thanks for staying, subscribe to my blog, and leave me a comment below.
Almost everyone heard about CDN but what that actually is?
Explained: CDN (Content delivery network) is the set of geographically distributed servers (proxy servers if you like) that cache the static content on running physical hardware which speeds up the actual download to its destination.
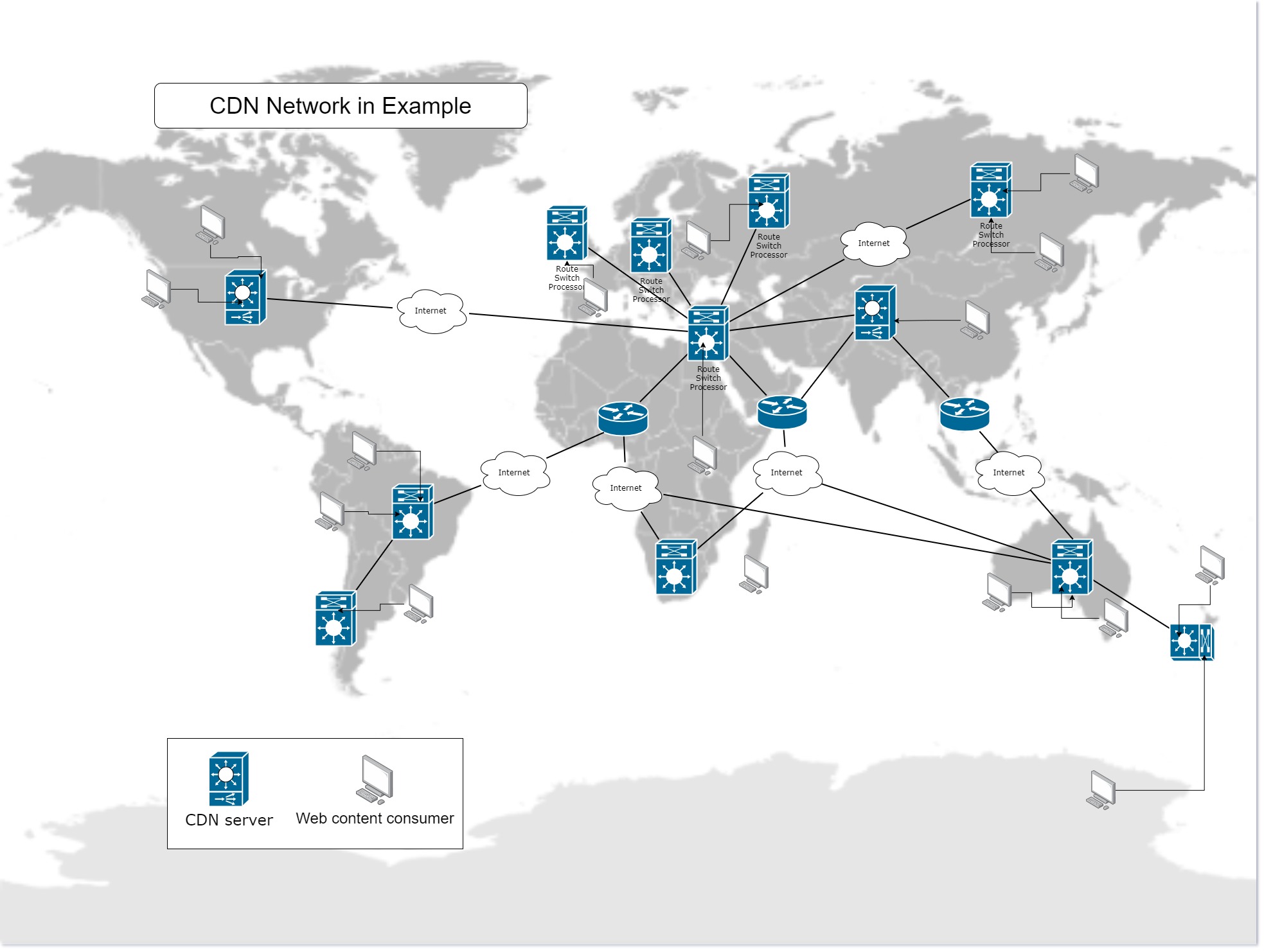
The global CDN network in Example
Now, let me explain why the CDN network is such a big player in the Solution infrastructure and why no Solution developer/architect should overlook this.
But before we go any further let me mention another term which is: response latency.
Explained: In other words, the time needed for to download the Website content entirely to the consumer (End-user) device.
And as you can imagine, this is another very important factor to have your eye on if want to keep your audience engaged to service-provided content as long as possible.
Low latency means a better User responsiveness/experience with the Website (Web service).
The question is, how to achieve the lowest latency possible? … there are two ways how to do it:
to use a very fast network for content delivery, or
to cache the content as closely as possible geographically to your audience
… the combination of both of these is the ultimate state towards which the global network is going (near real-time response).
And as all of you probably understand by now, to get the best ROI in the time you put into the content it is very important to have your infrastructure in the best shape possible. Keeping your visitors happy by serving them content as fast as possible helps to build better Website awareness and audience growth.
What CDN service provider do I use?
Among all of the CDN providers, I have come across, Cloudflare is the one I was attracted to most.
.. for many reasons:
The main one is that the service is offering reasonably good DDoS protection shielding and well-distributed and fast CDN server nodes.
Cloudflare account dashboard
To me, it is almost unbelievable that all of that for as much as $0! Yes, all of that can be yours for FREE! Very sweet deal, don’t you think? (btw, I am not participating in any affiliate program!)
Setting all of that up is a really straightforward and well-documented process.
The entire configuration process becomes even easier if having a domain name address purchased separately from the Web hosting (easier to maintain the DNS servers configuration over the Domain name provider portal – which every solid domain name provider has).
Another feature Cloudflare provides is the fast route finder across the Cloudflare network called Argo, which helps to decrease loading time and reduces bandwidth costs.
I have been using this service for one of my clients who is providing Address lookup and Address validation services over REST API web services hosted in the Cloud in multiple geographically different data centers and I must say that the customer experience has been very positive since.
In numbers, I was able to reduce an HTTP response latency time down from 1.4s to 0.5s! And these are very good performance improvements for a business where time is of the essence.
I am leaving this link here if interested to know more about this.
Anyway, thank you again for visiting this post, I hope you have enjoyed reading and let me know what CDN provider you’re using!
If seriously thinking about starting your career as a Frontend Software developer, you’re not going to do a bad turn with any of these Technical skills on the list below.
Especially for those who want to be demographically independent – aka, you’ll be able to find a job anywhere you go to maintain your cash flow…
From my working experience, these are the most resonating ones currently on the market (2021) in sequential order from the most wanted to down:
There are plenty of training materials online to start your journey.
But … I strongly recommend starting with the basics and principles first before jumping on core development. This can save you a lot of time in faulty code investigation and prevent unnecessary initial frustration (learning curve).
Btw., I am more like a person who learns from visual sources and I can give you a few tips on what I use for your start:
Mainly because software product deployments are becoming more frequent and Software houses and Service-oriented companies are pushing hard on the T2M (Time to Market) selling factor to keep them visible on the market.
Although all upcoming projects are prerequisites of non-functional requirements still the same (mainly),
the infrastructure design leveraging from Service Oriented Architecture
the solution must be scalable and automated to provision
the solution is capable of being hosted in the Cloud as well as on a hybrid network infrastructure
the solution is ISO 9126-compliant
first release completion time of 6 months
, amount of functional requirements needed for the first release keeps growing and in most cases does not help to achieve delivery in a given time.
And that is pretty bad.
Therefore “smart” selection of the frameworks and tools to use for building whatever investor wants to build a solution is an absolute must.
But, you won’t be able to succeed without the technical knowledge and experience of the production team! (the place where things are getting serious)
To get familiar with what skill sets to seek out while building a team capable of producing business value early from the beginning of project initiation, I have created a list of the suggested frameworks and platforms to use.
Hope it helps you to battle this constant competition market and investor pressure and elevate the progress in the initial phase of solution development as much as possible.
You are maybe already familiar with the term “low code”. The word on which many conceptual developers are rolling their eyes up. But hold on – if all that investors want is to get the product out of the door as soon as possible and for the cost related to head x time spent on the project (which would probably be somewhere around 50% less as opposed to the traditional way of coding in this case), just give it to them!
Every solid developer must be familiar with this PaaS these days if not with Outsystems then with some other alternative such as PowerApps, for example.
Heyou – all Node.js Devs are lifting their eyebrow. Yes, very powerful framework, indeed. Usage of LoopBack CLI cannot be easier thanks to documentation built by many contributors from this OpenSource project.
Simply put, this framework allows you to build your complete backend infrastructure with speed which elevates your project progress exponentially. You can choose from REST, SOAP, GraphQL, and RPC servers/services and manage all of these nodes with PM2 process management systems.
Don’t forget about a testing framework. This option will work well with the ones mentioned above and you cannot go wrong with learning this framework right away. Javascript is rocking all over the globe right now and would be silly not to pay any attention to this programming language intentionally.
And so why not leverage the JavaScript syntax in every SDLC phase? Sounds logical, hm?
This CLI utility from AWS is becoming more and more popular among developers from generation Y. Nobody likes to deal with building the infrastructure on the DevOps level unless it’s ABSOLUTELY necessary. And to be fair a lot of the service provisioning commands can be easily automated.
Therefore, a utility that scaffolds everything you need for hosting your system is a necessary skill these days.
If not going to use any of these “low code” platforms mentioned above for building your solution, a solid provisioning automation system (“engine”) and paradigm for not only infrastructure automation provisioning but also for keeping track of infrastructure changes in source code is the must. You cannot go wrong with Azure DevOps/ARM Templates or Terraform. Both offer you a lot of capabilities and automation to follow the IoC (Infrastructure as a code) paradigm.
To me, Terraform is a better option for those thinking of incorporating platforms of different technologies into the solution.
PS: The technology cannot set the project for success if architecture, design, and test automation are compromised. Not having the right team, implemented processes, following the best practices, and a need to keep good progress momentum on the project, your entire ship can turn in the opposite direction and end up with catastrophic failure.
This is all for today, hope you enjoyed this reading today, and leave me your thoughts down below in the comments!
Thanks for staying, subscribe to my blog and leave me a comment below.
Is your system working with price items with values more than 2 decimal points long? Are you using rounding as a part of the calculating formula? Have you generated an invoice from Xero API and later found out that the actual total on it is a few cents off?
If the answers to all of these questions are yes, you are at the right place!
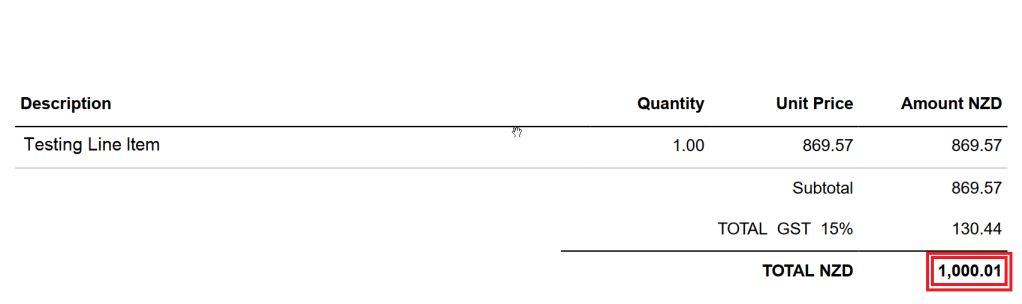
Well, you know this story … you have done all that hard work on building Xero API integration, happy with finishing the project on time and with such a masterpiece level source code, and in the first integration test run you discover that your invoice calculated data summary data are different from what Xero has generated in the invoice (ouch!):
Invoice line items total calculation with one cent off
And yes, something is not looking right, and scratching the head does not seem to be helping much …
Well, the truth is that every system does invoice calculation of subtotal, total, and GST differently. The same applies to the Xero backend service (API) and therefore these two ways are good options to get you out of the trouble.
One way of doing it is to add an adjustment line as a part of the Xero API request payload and put the variation value into it to keep source data in alignment with Xero. Personally, I don’t really like this approach. The reason being is that you are going to end up with a more comprehensive solution for not much-added business value as appose to the time spent on building it.
Another way is to follow the Xero calculation formula. Yep, you heard me right…
And the way I would rather suggest you go with. You may be asking why I would do that?
So let me explain my view on this.
Let’s assume that Xero as a business is on the market for several decades now. You may be getting some sense about the overall knowledge Xero as a company must have gained from such a long time history, of providing comprehensive financial services to customers.
I also know that Xero has gone through several business validation iterations and internal system refactoring processes to build as much accurate tax calculation business logic on the API backend as possible. All these company journeys supported by customer feedback and over time accumulating domain knowledge helped Xero build a great service reputation in the current market worldwide.
And the question is, why wouldn’t I use this knowledge to my advantage? And just btw – I am not participating in any affiliate programs running by Xero!
Do you have another thought about it? – leave me a comment below 😉
Ok, let’s go ahead and talk about the calculation formula…you can start to calculate GST from the prices either GST inclusive or exclusive. These are the types of line items on request payload.
Types of line items to be used in the invoice request payload
1. Line item price with GST exclusive
Round line-item-price to 2 DP (decimal places) Round(line-item-price) => Round2DP(10.5456)
Calculate line-item GST from rounded line-item-price, line-item-quantity, and GST rate, and round the result to 2 DP for each line-item Round(line-item-price * [GST rate] * line-item-quantity) => Round2DP(10.55*(0.155) *5)
Sum up the rounded line-item-price(s) as Subtotal (line-item-price * line-item-quantity)+…N(row)…+(line-item-price * line-item-quantity)
Sum-up the line-item calculated GST (step2) as GST Total (step2)+…N(row)…+(step2)
Add Subtotal and GST Total as invoice Total (step3)+(step4)
Feels difficult? That is ok. For simplicity and quick integration reasons, I have created the NuGet package XeroGSTTaxCalculation (NET 5) for you, free to use.
A short demonstration of how to use the XeroGSTTaxCalculation NuGet package:
class Program
{
static void Main(string[] args)
{
IXeroTaxCalculationService service = new XeroTaxCalculationService();
var data = new[] {
new LineItem { Code = "code_1", Price = 12m, Quantity = 10 },
new LineItem { Code = "code_2", Price = 8.7998m, Quantity = 8 }
};
var invoiceDetails = service.CalculateGSTFromPriceGSTExclusive(data, 0.25);
Console.WriteLine(invoiceDetails);
Console.ReadLine();
}
}
2. Line item price with GST inclusive
Add 1 to the GST rate 1+[GST rate] => 1 + 0.15
Calculate and Round to 2 DP line-item-price as line-item-price-total Round(line-item-price*line-item-quantity) => Round2DP(10.5456*5)
Divide rounded line-item-price-total by GST rate (for each line-item) and round to 2 DP as line-item-price-lessTax Round(line-item-price-total/[GST rate] )=> Round2DP(52.73/1.15)
Subtract line-item-price-lessTax from line-item-price-total as line-item-gst (line-item-price-total ) – (line-item-price-lessTax)
Sum-up the line-item calculated GST (line-item-gst) as invoice GST total (step4)+…N(row)…+(step4)
Sum-up line-item-price-total as invoice Total (step2)+…N(row)…+(step2)
Subtract GST total from Total to get invoice Subtotal (step6) – (step5)
Feel free to use NuGet package XeroGSTTaxCalculation for this as shown in one code example from above. I bet you’re gonna need this saved time to spend on beer sessions with your mates instead .). Cheers!
The most used infrastructure architecture for SMEs and data-oriented small businesses operating on a global scale.
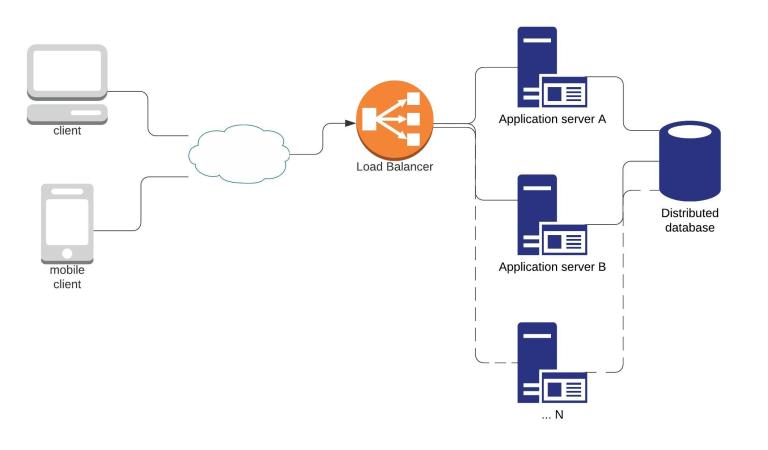
When it comes to the technology stack, and if talking about Web Applications then the most common setup I have seen all over the place is React.js being used for SPA or PWA frontend as a client/presentation layer, node.js as a Rest API Server/business layer and Cassandra (open source) as distributed (optionally cloud-based), fault-tolerant, well-performed, durable, elastic, …, supported (don’t forget on decent support from the community!), decentralized and scalable database/persistent layer.
Your database does not have to tick all of these boxes from above (apart from being distributed), but if you’re going to put all that effort into building this type of infrastructure, you want to make sure that the database meets as many required features from being modern and long-lasting solution sitting in infrastructure as possible (think about your development ROI Devs!!).
The way it works is that the client application (fetched from the store or application server) is capable of handling the user tasks by itself on the client device with the data supported over the API (node.js) and in the event of Server API running out of the breath, a new instance of the Application API server will be provisioned (new node is getting created, horizontal scaling -> scaling out/in).
Database, as it stands in this model, does not have this scaling capability but can scale up or down instead as needed (service is given more system resources, vertical scaling -> scaling up/down).
An illustration of how it’s getting all wired up together
1.1 Modern 3-Tier Distributed System Architecture
Summary
Pros
great logical separation and isolation with a lot of room for cybersecurity policy integration
not-complex architecture when it comes to problem investigation and troubleshooting
easy to medium complexity to get the infrastructure up and ready for development and maintenance (less DevOps, yay!)
an easy option to replicate infrastructure on user localhost for development purposes (just makes it all easier during branch development)
infrastructure running cost is relatively small
Cons
decommissioning provisioned nodes can be tricky (depending on the technology used)
data synchronization and access need orchestration (subjected to database type)
shipping new features out needs an entire Application server deployment (downtime)
Thanks for staying, subscribe to my blog and leave me a comment below.