
Is your system working with price items with values more than 2 decimal points long? Are you using rounding as a part of the calculating formula? Have you generated an invoice from Xero API and later found out that the actual total on it is a few cents off?
If the answers to all of these questions are yes, you are at the right place!
Well, you know this story … you have done all that hard work on building Xero API integration, happy with finishing the project on time and with such a masterpiece level source code, and in the first integration test run you discover that your invoice calculated data summary data are different from what Xero has generated in the invoice (ouch!):
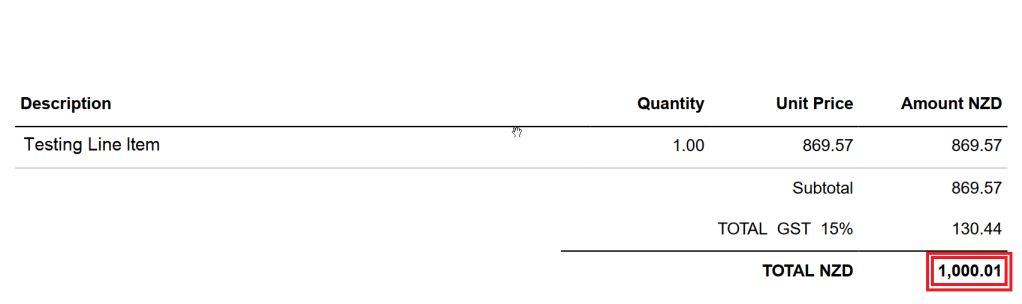
And yes, something is not looking right, and scratching the head does not seem to be helping much …
Well, the truth is that every system does invoice calculation of subtotal, total, and GST differently. The same applies to the Xero backend service (API) and therefore these two ways are good options to get you out of the trouble.
One way of doing it is to add an adjustment line as a part of the Xero API request payload and put the variation value into it to keep source data in alignment with Xero. Personally, I don’t really like this approach. The reason being is that you are going to end up with a more comprehensive solution for not much-added business value as appose to the time spent on building it.
Another way is to follow the Xero calculation formula. Yep, you heard me right…
And the way I would rather suggest you go with. You may be asking why I would do that?
So let me explain my view on this.
Let’s assume that Xero as a business is on the market for several decades now. You may be getting some sense about the overall knowledge Xero as a company must have gained from such a long time history, of providing comprehensive financial services to customers.
I also know that Xero has gone through several business validation iterations and internal system refactoring processes to build as much accurate tax calculation business logic on the API backend as possible. All these company journeys supported by customer feedback and over time accumulating domain knowledge helped Xero build a great service reputation in the current market worldwide.
And the question is, why wouldn’t I use this knowledge to my advantage? And just btw – I am not participating in any affiliate programs running by Xero!
Do you have another thought about it? – leave me a comment below 😉
Ok, let’s go ahead and talk about the calculation formula…you can start to calculate GST from the prices either GST inclusive or exclusive. These are the types of line items on request payload.
Types of line items to be used in the invoice request payload
1. Line item price with GST exclusive
- Round line-item-price to 2 DP (decimal places)
Round(line-item-price) => Round2DP(10.5456) - Calculate line-item GST from rounded line-item-price, line-item-quantity, and GST rate, and round the result to 2 DP for each line-item
Round(line-item-price * [GST rate] * line-item-quantity) => Round2DP(10.55*(0.155) *5) - Sum up the rounded line-item-price(s) as Subtotal
(line-item-price * line-item-quantity)+…N(row)…+(line-item-price * line-item-quantity) - Sum-up the line-item calculated GST (step2) as GST Total
(step2)+…N(row)…+(step2) - Add Subtotal and GST Total as invoice Total
(step3)+(step4)
Feels difficult? That is ok. For simplicity and quick integration reasons, I have created the NuGet package XeroGSTTaxCalculation (NET 5) for you, free to use.
A short demonstration of how to use the XeroGSTTaxCalculation NuGet package:
class Program
{
static void Main(string[] args)
{
IXeroTaxCalculationService service = new XeroTaxCalculationService();
var data = new[] {
new LineItem { Code = "code_1", Price = 12m, Quantity = 10 },
new LineItem { Code = "code_2", Price = 8.7998m, Quantity = 8 }
};
var invoiceDetails = service.CalculateGSTFromPriceGSTExclusive(data, 0.25);
Console.WriteLine(invoiceDetails);
Console.ReadLine();
}
}
2. Line item price with GST inclusive
- Add 1 to the GST rate
1+[GST rate] => 1 + 0.15 - Calculate and Round to 2 DP line-item-price as line-item-price-total
Round(line-item-price*line-item-quantity) => Round2DP(10.5456*5) - Divide rounded line-item-price-total by GST rate (for each line-item) and round to 2 DP as line-item-price-lessTax
Round(line-item-price-total/[GST rate] )=> Round2DP(52.73/1.15) - Subtract line-item-price-lessTax from line-item-price-total as line-item-gst
(line-item-price-total ) – (line-item-price-lessTax) - Sum-up the line-item calculated GST (line-item-gst) as invoice GST total
(step4)+…N(row)…+(step4) - Sum-up line-item-price-total as invoice Total
(step2)+…N(row)…+(step2) - Subtract GST total from Total to get invoice Subtotal
(step6) – (step5)
Feel free to use NuGet package XeroGSTTaxCalculation for this as shown in one code example from above. I bet you’re gonna need this saved time to spend on beer sessions with your mates instead .). Cheers!
For more information about rounding, visit the Xero documentation site for developers.
Thanks for staying, subscribe to my blog, and leave me a comment below.
cheers\




