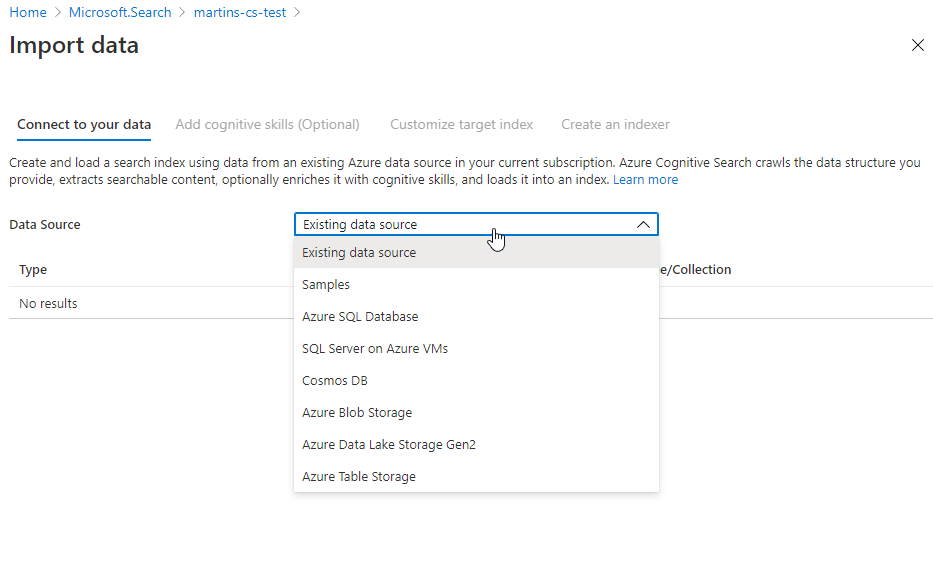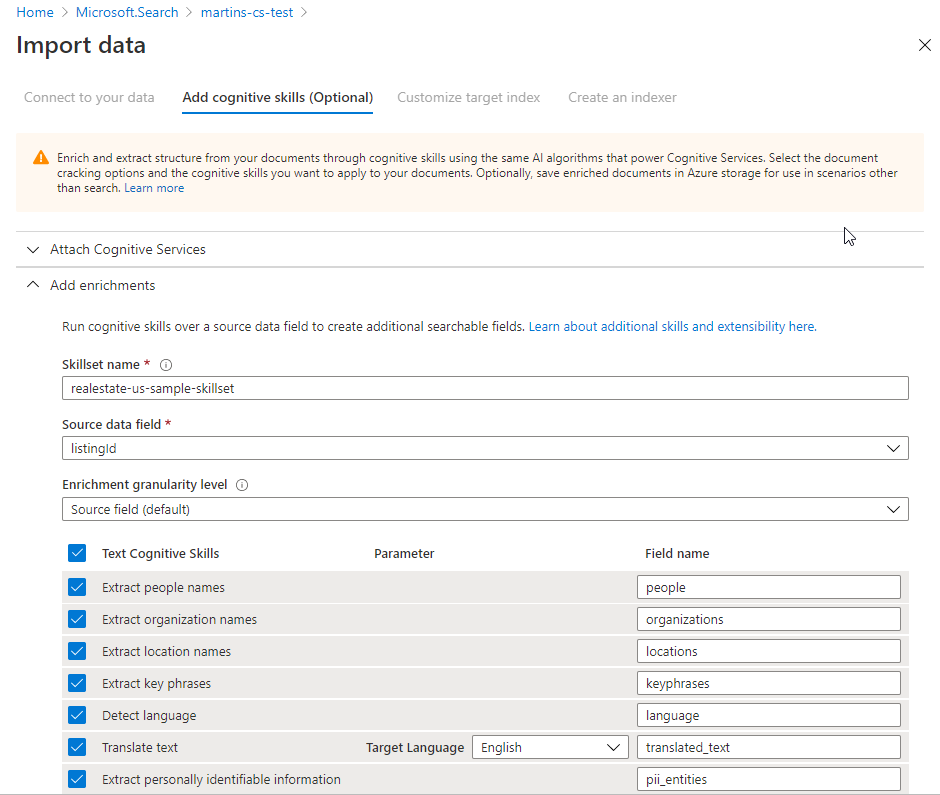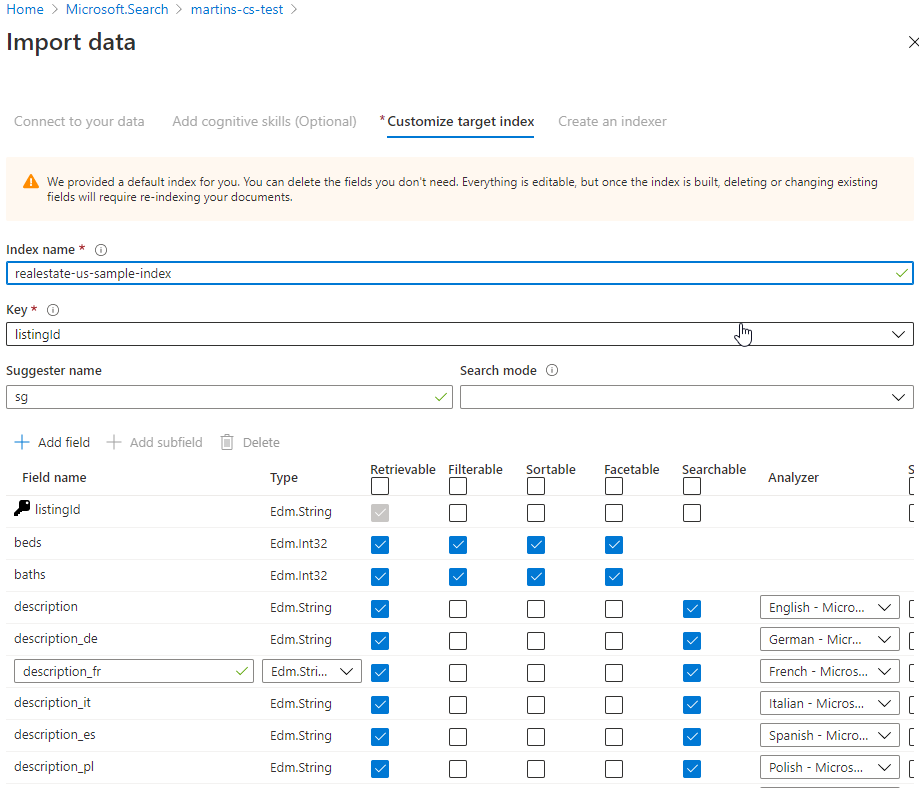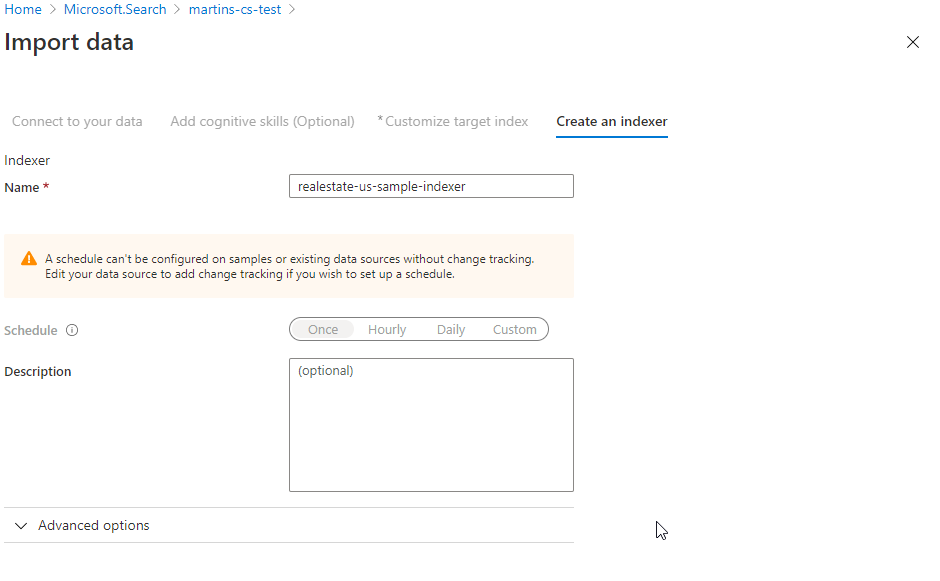

Although today’s way of software development is rapidly changing, having a good understanding of these principles and good practices may only help you become better in software development.
Personally, I would recommend to every solid Software Engineer to get familiar with these practices if not already.
Coding practices
- YAGNI (You Aren’t Gonna Need It)
- DRY (Don’t Repeat Yourself)
- SOLID principles
- KISS principles (Keep It Simple, Stupid)
- BDD (Behavior-Driven Development)
- TDD (Test-Driven Development)
- FDD (Feature-Driven Development)

YAGNI
This principle came from Extreme Programming and states very simple things: Don’t overthink the problem solution in the execution stage.
Just write enough code to make things work!
DRY
This principle follows and states for: “Every piece of knowledge must have a single, unambiguous, authoritative representation within a system.”
Basically, don’t replicate functionality in the system, and make your code reusable.
SOLID
This principle has its own space in OOP. The SOLID mnemonic acronym represents these five design principles:
- Single-responsibility
Design your classes in structural business entity/domain hierarchy, so that only one class encapsulates only logic related to it. - Open-closed
Entities should be open for extension but closed for modification.
In the development world, any class/API with publicly exposed methods or properties should not be modified in their current state but extended by other features as needed. - Liskov substitution
This principle defines the way how to design classes when it comes to inheritance in OOP.
The simplified base definition says that if class B is a subtype of class (super) A, then objects of A may be replaced with objects of type B without altering any of the desirable properties of the program.
In other words, if you have a (super) class of type Vehicle and subclass of type Car, you should be able to replace any objects of Vehicle with the objects Car in your application, without breaking application behavior or its runtime. - Interface segregation
In OOP is recommended to use Interfaces as an abstracted segregation level between the producer/consumer modules. This creates an ideal barrier preventing coupling dependencies and exposing just enough functionality to the consumer as needed. - Dependency inversion
The principle describes a need for abstract layer incorporation between the modules from top to bottom hierarchy. In brief, a high module should depend on an abstract layer (interface), and a lower module with dependency on the abstract layer should inherit/implement it.
KISS
Acronym for Keep it simple, stupid – and my favorite over the last years!
The principle has a very long history but has been forgotten by many Devs many times from my professional experience.
Avoiding unnecessary complexity should be in every solid Software Engineer’s DNA.
This keeps the additional development cost down for further software maintenance, new human resources onboarding, and the application/system’s additional organic growth.
BDD
Behavior-driven development is becoming a more and more desirable practice to follow in Agile-oriented business environments.
The core of these principles is coming from FDD. The BDD applies a similar process at the level of features (usually a set of features). One’s tests build the application/system is getting a return on investment in the form of automated QA testing for its lifetime. And therefore this way of working is very economically efficient in my opinion.
The fundamental idea of this is to engage QAs (BAs) in the development process right from the beginning.
This is a great presentation of the principle from the beginning to the end of the release lifecycle: Youtube
TDD
The software development process gained its popularity over time in test automatization. Basics come from the concept of starting the test first and following with the code until the test runs successfully.
Leveraging Unit test frameworks for this such as xUnit, NUnit (or similar), if you are a .NET developer, helps to build a code coverage report very easily in MS Visual Studio (Enterprise edition) for example, which helps to build QA confidence over the code which last long time over the code releases.
FDD
Well, know approach how to deliver the small blocks (features) in an Agile running environment.
In other words, if you have a load of work to deliver is better to slice it down to individual blocks (features) that can be developed, tested, and delivered independently.
The whole FDD methodology has 5 stages:
- Develop a model of what is needed to build
- Slice this model into small, testable blocks (features)
- Plan by feature (development plan – who is going to take that ownership)
- Design by feature (selects the set of features the team can deliver within the given time frame)
- Build by feature (build, test, commit to the main branch, deploy)
The beauty of this development methodology approach is that deployment features such as Feature toggling can be integrated with relatively minimal complexity overhead. With this integration in place, the production team can move forward only on one main branch, an unfinished feature development state regardless. An enterprise-level production team will appreciate this advantage, no doubt about it.
Summary
By following these principles and practices production team will produce maintainable code, with high test coverage and human resources high utilization over the SDLC (ROI).

Thanks for staying, subscribe to my blog and leave me a comment below.
cheers\